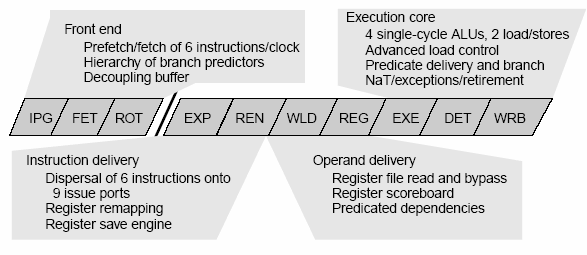
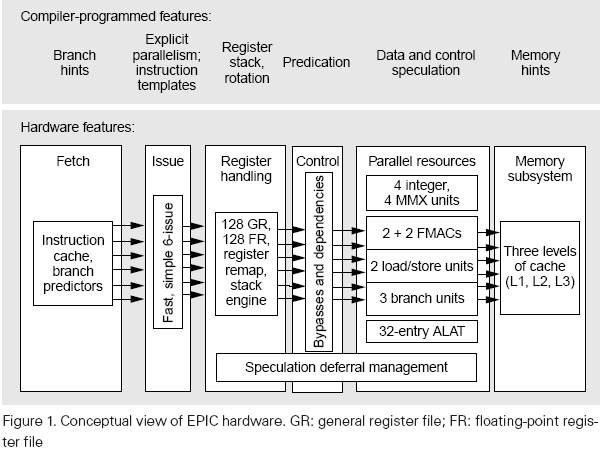
Deep pipelining (10 stages)
IPG - Instruction Pointer Generation
FET - Fetch
ROT - Rotate
EXP - Expand
REN - Rename
WL.D - Word-Line Decode
REG - Register Read
EXE - Execute
DET - Exception Detect
WRB - Write-Back
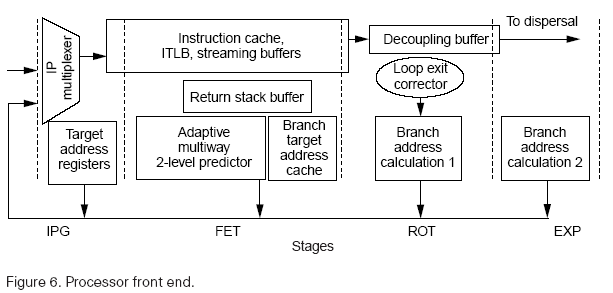
Above figure illustrates the 10-stage core pipeline. The bold line in the middle of the core pipeline indicates a point of decoupling in the pipeline. The pipeline accommodates the decoupling buffer in the ROT (instruction rotation) stage, dedicated register-remapping hardware in the REN (register rename) stage, and pipelined access of the large register file across the WLD (word line decode) and REG (register read) stages. The DET (exception detection) stage accommodates delayed branch execution as well as memory exception management and speculation support.
Prefetching with predication
Data prefetching can effectively hide memory access latency. It works by overlapping the time to access a memory location with computation time as well as with the time to access other memory locations. The compiler inserts prefetch instructions for selected data references at carefully chosen points in the program, so that referenced data items are moved as close to the processor as possible before the data items are actually used. Prefetch instructions (named lfetch in IA-64) have one argument: the address to be prefetched. The instructionˇŻs effect is to move the cache line containing the address to a higher level of the memory hierarchy. The address itself has no cache alignment requirement.
Prefetching with rotating registers
IA-64ˇŻs rotating registers can alleviate the increase in resource requirements while prefetching. Multiple arrays accessed uniformly within a loop can be prefetched with a single lfetch instruction using a rotating register that rotates the addresses of the different arrays that must be prefetched. This obviates the need for predicate calculations within the loop and saves memory slots that would otherwise be occupied by multiple lfetch instructions.