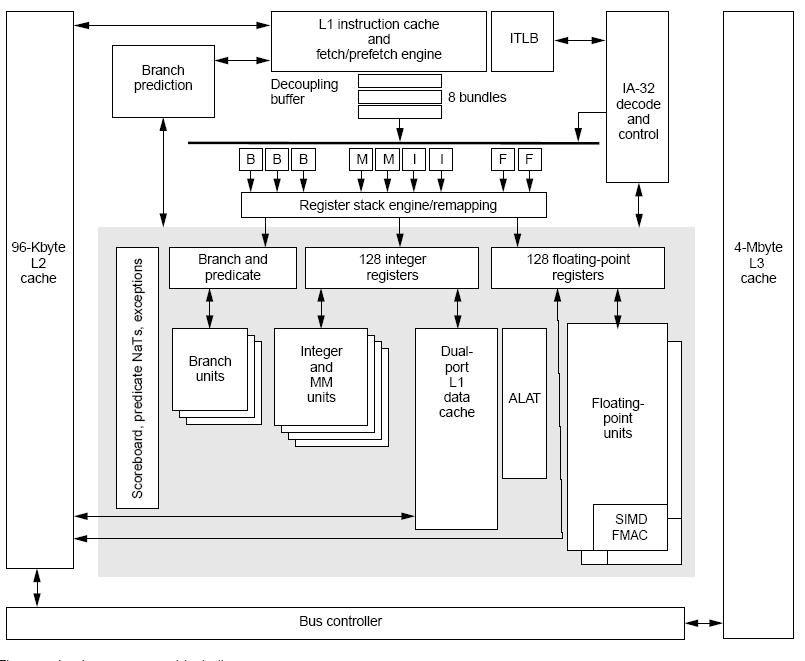
Interconnection Structures
System bus
The processor uses a multidrop, shared system bus to provide four-way glueless multiprocessor system support. No additional bridges are needed for building up to a four-way system. Systems with eight or more processors are designed through clusters of these nodes using high-speed interconnects. Note that multidrop buses are a cost-effective way to build high-performance four-way systems for commercial transaction processing and e-business workloads. These workloads often have highly shared writeable data and demand high throughput and low latency on transfers of modified data between caches of multiple processors. In a four-processor system, the transactionbased bus protocol allows up to 56 pending bus transactions (including 32 read transactions) on the bus at any given time. An advanced MESI coherence protocol helps in reducing bus invalidation transactions and in providing faster access to writeable data. The cache-to-cache transfer latency is further improved by an enhanced ˇ°defer mechanism,ˇ± which permits efficient out-of-order data transfers and out-of-order transaction completion on the bus. A deferred transaction on the bus can be completed without reusing the address bus. This reduces data return latency for deferred transactions and efficiently uses the address bus. This feature is critical for scalability beyond four-processor systems. The 64-bit system bus uses a source-synchronous data transfer to achieve 266-Mtransfers/ s, which enables a bandwidth of 2.1 Gbytes/s. The combination of these features makes the Itanium processor system a scalable building block for large multiprocessor systems.
Source Synchronous Mode
In source synchronous mode, the clock to data phase relationship at the input pins is maintained at the clock and data ports of the IOE input register. This mode is recommended for source synchronous data transfers. Data and clock signals at the IOE experience similar buffer delays as long as the same I/O standard is used.
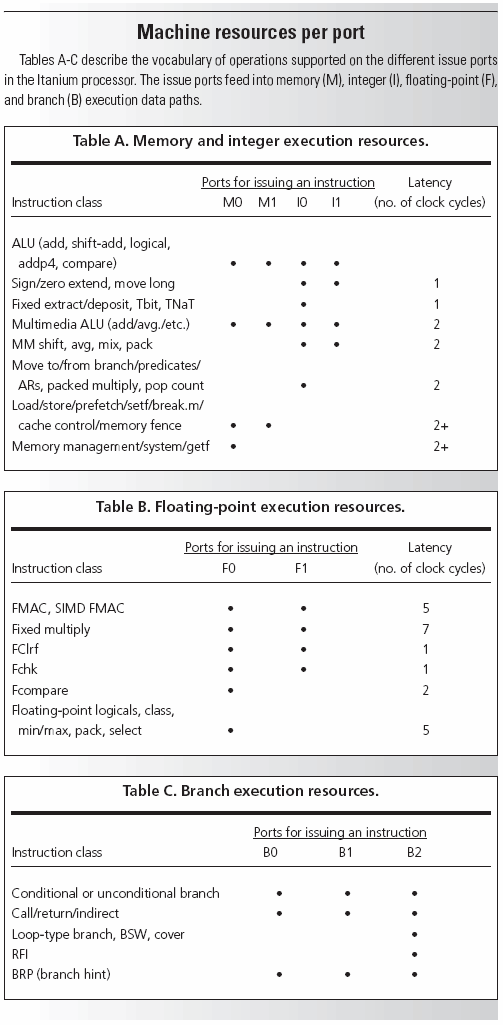
An alternative approach to multiple operations per cycle is reflected in an instruction set design that resembles horizontal microinstructions; this approach is called VLIW, standing for very long instruction word. In this approach, it is up to the compiler to completely determine data and resource dependencies among multiple operations and pack them into instruction words so that there will be no conflicts during execution. It is not surprising that Josh Fisher has been a major leader in VLIW computer design and that trace scheduling has been used to optimize VLIW programs.
A derived form of VLIW is planned for the Intel IA-64 instruction set. The design principles, pioneered by HP as well as Intel, are collectively called EPIC, standing for explicitly parallel instruction computing. The IA-64 instruction set will group three instructions per "bundle" and provide explicit dependency information. The dependency information must be determined by the compiler and will be used by the hardware to schedule the execution of the instructions. Therefore a processor designed according to the EPIC principles stands somewhere between a superscalar and a VLIW. EPIC also calls for predication, a technique that uses a set of predicate registers, each of which can hold a value of true or false. Rather than executing branch instructions to implement an if-then-else control structure within the program, the operations involved can be predicated (i.e., made conditional) on a given predicate register. Thus, operations from both the then-path and the else-path can flow through the pipeline without any disrupting branches, but only one set of operations will be allowed to write results back.
High-performance or low-power design is not merely a matter of deciding upon the types and levels of parallel activities and predictions supported by the datapath. The optimal use of any datapath requires an appropriate level of compiler optimization technology. This may include machine-independent optimizations such as constant-folding and procedure inlining as well as machine-dependent optimizations such as instruction scheduling for pipelines and array-tiling for caches. Moreover, the new EPIC designs will require even more aggressive code optimizations to obtain the best performance.