Virtual Memory Size
64 bit memory address -> 2^64 bytes
Variable Page Sizes Variable Page Sizes
Minimum on all implementations Minimum on all implementations
–4K, 8K, 16K, 64K, 256K, 1M, 4M, 16M, 4K, 8K, 16K, 64K, 256K, 1M, 4M, 16M, 64M, 256M 64M, 256M-bytes bytes
4 GB purge 4 GB purge
–Simplify address space de Simplify address space de-allocation

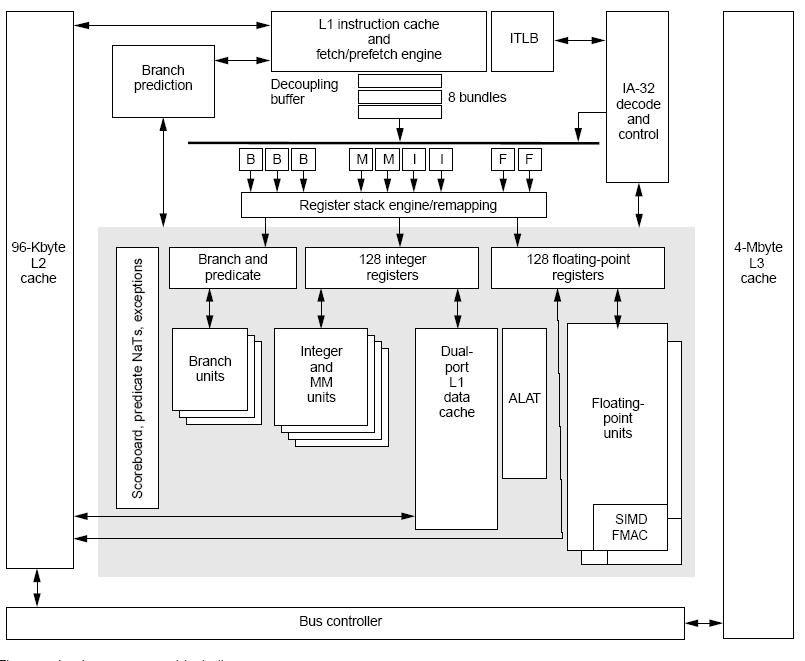
Memory subsystem
In addition to the high-performance core,
the Itanium processor provides a robust cache
and memory subsystem, which accommodates
a variety of workloads and exploits the
memory hints of the IA-64 ISA.
Three levels of on-package cache
The processor provides three levels of onpackage
cache for scalable performance across
a variety of workloads. At the first level, instruction
and data caches are split, each 16 Kbytes
in size, four-way set-associative, and with a 32-
byte line size. The dual-ported data cache has
a load latency of two cycles, is write-through,
and is physically addressed and tagged. The L1
caches are effective on moderate-size workloads
and act as a first-level filter for capturing the
immediate locality of large workloads.
The second cache level is 96 Kbytes in size,
is six-way set-associative, and uses a 64-byte
line size. The cache can handle two requests per
clock via banking. This cache is also the level at
which ordering requirements and semaphore
operations are implemented. The L2 cache uses
a four-state MESI (modified, exclusive, shared,
and invalid) protocol for multiprocessor coherence.
The cache is unified, allowing it to service
both instruction and data side requests
from the L1 caches. This approach allows optimal
cache use for both instruction-heavy (server)
and data-heavy (numeric) workloads. Since
floating-point workloads often have large data
working sets and are used with compiler optimizations
such as data blocking, the L2 cache
is the first point of service for floating-point
loads. Also, because floating-point performance
requires high bandwidth to the register file, the
L2 cache can provide four double-precision
operands per clock to the floating-point register
file, using two parallel floating-point loadpair
instructions.
The third level of on-package cache is 4
Mbytes in size, uses a 64-byte line size, and is
four-way set-associative. It communicates
with the processor at core frequency (800
MHz) using a 128-bit bus. This cache serves
the large workloads of server- and transactionprocessing
applications, and minimizes the
cache traffic on the frontside system bus. The
L3 cache also implements a MESI protocol
for microprocessor coherence.
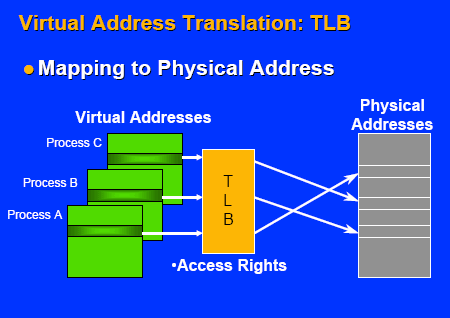
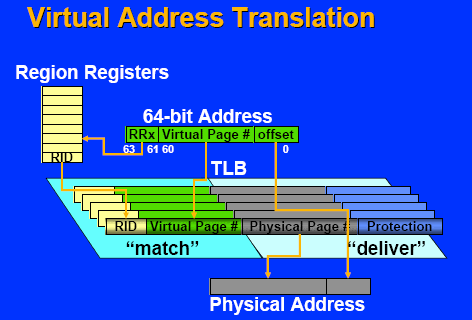
A two-level hierarchy of TLBs handles virtual
address translations for data accesses. The
hierarchy consists of a 32-entry first-level and
96-entry second-level TLB, backed by a hardware
page walker.
Optimal cache management
To enable optimal use of the cache hierarchy,
the IA-64 instruction set architecture
defines a set of memory locality hints used for
better managing the memory capacity at specific
hierarchy levels. These hints indicate the
temporal locality of each access at each level of
hierarchy. The processor uses them to determine
allocation and replacement strategies for
each cache level. Additionally, the IA-64 architecture
allows a bias hint, indicating that the
software intends to modify the data of a given
cache line. The bias hint brings a line into the
cache with ownership, thereby optimizing the
MESI protocol latency.
Table 2 lists the hint bits and their mapping
to cache behavior. If data is hinted to be nontemporal
for a particular cache level, that data
is simply not allocated to the cache. (On the L2
cache, to simplify the control logic, the processor
implements this algorithm approximately.
The data can be allocated to the cache, but the
least recently used, or LRU, bits are modified
to mark the line as the next target for replacement.)
Note that the nearest cache level to feed
the floating-point unit is the L2 cache. Hence,
for floating-point loads, the behavior is modi-
fied to reflect this shift (an NT1 hint on a floating-
point access is treated like an NT2 hint on
an integer access, and so on).
Allowing the software to explicitly provide
high-level semantics of the data usage pattern
enables more efficient use of the on-chip
memory structures, ultimately leading to
higher performance for any given cache size
and access bandwidth.